

“We tend to think of technological advances as destroying what’s gone before, but that doesn’t usually happen. This could lead to a different way of making music.”
– Jarvis Cocker, former Pulp frontman, solo artist, writer and broadcaster

Jarvis Cocker hosting Future Technologies in Music, a panel discussion at The Science Museum on Wednesday 30th January.
In recent years, the development of music technology has tended towards incremental changes, iterating on existing approaches to sound synthesis and refining tools such as sequencers and effect plugins. In some ways the industry occupies an almost contradictory space, soaking up whatever CPU power that is available often to better run simulations of the retro gear of the ‘70s and ‘80s. Companies such as Korg, Roland and Behringer, who recently announced the hugely competitively priced Crave, a £150 semi-modular analogue synth, are pushing their businesses forward by looking backwards.
Into this mix steps the disruptive technologies of AI and machine learning. Can these be used to convincingly simulate the creative process of an accomplished performer or composer?
In May 2017 at the Future of Go summit, the AI AlphaGo now famously presented its human opponent with a move so entirely unexpected, it shocked players of the game and resulted in a re-evaluation of how it could be played. Sam Potter from the Future Technologies in Music panel at the Science Museum described the impact of this event.
“This one move it did was so strange, unique and bizarre and creative that it opened up a whole new part of the game and our understanding of how to play.”
Neural networks are capable of reframing possibilities and moving outside of traditional expectations, but the nature of the reinforced learning approach means it necessarily does so opaquely; the process that leads to the result is inherently obscured and unpredictable.
Starting with Google DeepMind’s WaveNet, there have been various attempts to harness the potential of machine learning in the sound and music fields. Creating believable speech is the auditory equivalent of the uncanny valley phenomenon, as it demands both a realistic synthetic model of how speech sounds and the intonation – how it’s performed. Encoding contextually appropriate inflections is a massive challenge. We’re often alerted to the generated nature of synthetic speech because of our sensitivity to inaccuracies in the speed, pitch or general delivery of the words. Wavenet and Microsoft’s neural network-powered speech generation demos use algorithms that have been trained on real human speech which enables the synthesis model to create a considerably more convincing performance, surpassing traditional speech synthesis methods.
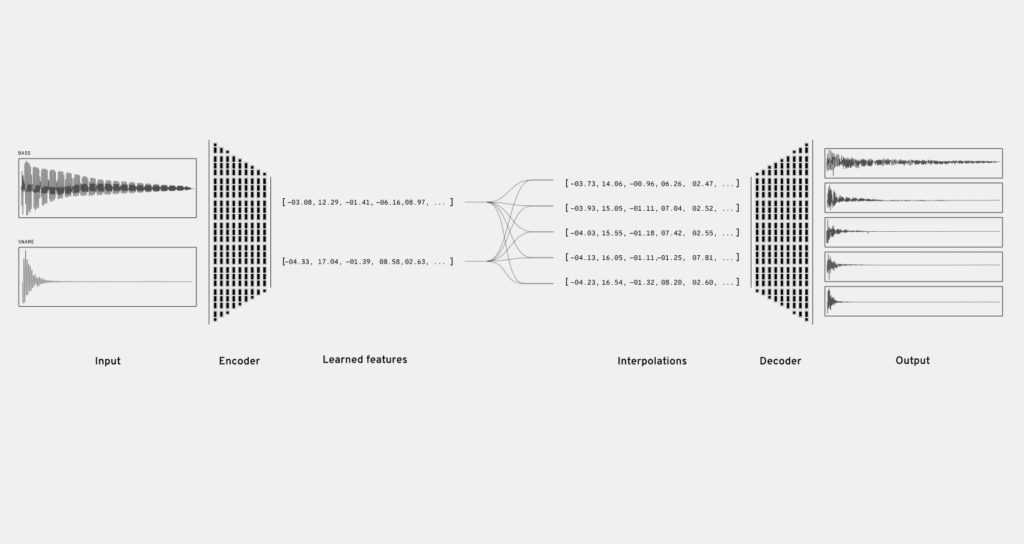
Google’s Nsynth
Leading on from Wavenet, Google’s Magenta team has used Tensorflow, a GPU accelerated machine learning library, to experiment with building a synthesiser. NSynth (Neural Synthesizer) analyses pairs of existing sounds to construct a new instrument that is related but clearly different from its parents. The encoder stage looks at the quality and characteristics of the source instruments as well as their temporal nature, to produce a result that would be difficult to create by hand using traditional synthesis methods.
In the 1990s, SSEYO’s Koan software found fame when Brian Eno used it to create his floppy disc-based album, ‘Generative Music 1’. It was an early example of
“The idea of an AI making effective music that we like? Brian Eno puts this at around six or seven years.” – Sam Potter, musician and author

Creature generation table, No Man’s Sky.
All the creatures in No Man’s Sky are procedurally generated and each needed an authentic sound to accompany them.
It is this performance aspect of machine learning where the greatest potential perhaps lies. In the game No Man’s Sky, we used a physically modeled vocal tract to create the sounds of the procedurally generated creatures. However to sound at all convincing, the synthesiser needed to be performed, similar to playing an instrument. Using an algorithmic method to drive the performance, such as Perlin noise, translated poorly to the timed-based audio domain resulting in the creatures sounding robotic and stilted. Our solution of driving the vocals using a MIDI-based library of performance-captured phrases worked adequately enough, but to have had the ability to learn and then extrapolate different emotional states through a process of training based on a wide variety of source material would have been a far preferable scenario.
It’s not just in the areas of sound generation or music performance where these technologies are having an impact. Mastering is the last stage of mixing before the music is distributed, where the track has a range of DSP effects applied, such as compression and EQ, to give the music its final polish. Businesses such as the music mastering and distribution company LANDR uses machine learning to enable artists to choose a mastering style to best match the genre of the music being processed, the styles being derived from a process of training based around existing material.
The uses of machine learning in audio production are impressively varied, from creating new sounds, coming up with human-like performances through to the final preparation. What these tools have in common is the ability to augment the creative process, rather than supplant it, to offer new opportunities, all the while relying on the artist to form their own creative decisions.



