


A unified architecture means that the ALUs (Arithmetic Logic Units – the bits of the hardware that do all the number crunching as part of shader or compute program processing) are generic and not dedicated to specific processing tasks.
This type of ‘universal (or unified) shading’ approach is unanimously recognised as the most efficient. Unified shaders execute tasks efficiently, irrespective of the balance between vertex and pixel (or compute) processing tasks, by always using all the ALU resource available.
Typically these ALU designs in GPUs are multithreaded to help hide memory latency (the delay between the hardware requesting data for processing and the data actually becoming available for processing) where threads are different vertices, pixels or compute elements. By running over many elements, the hope is that by the time you get back to the first element, the data it needs will have become available.
Multithreading and multitasking ALUs for efficiency
Imagination takes the efficiency concept to the next level by not only allowing multiple ‘threads,’ but also by allowing these threads to belong to different ‘tasks’. What this means is that latency is not only absorbed by having lots of pixels or vertices or compute operations in-flight (threads of a single task), but by actually allowing all of these multiple ‘tasks’ to be operated upon based on data availability.
By enabling multitasking, the hiding of latency and efficiency of processing become far more effective than by simply having lots of elements devoted to the same single task. Independent tasks have a higher chance of having data available for processing than just a single task (basically if data goes missing for one element, it’s likely it goes missing for all elements of that same task). With independent tasks, this condition is avoided.
Some vendors falsely claim that non-unified processing is more power–efficient. Their flawed argument in support of this claim is based around the ability to turn vertex processing blocks off when geometry processing is completed. This reasoning ignores the simple fact that unified designs can also turn off fixed function processing blocks related to geometry processing. And the ALUs in such a unified design ultimately speed up pixel processing, which thus completes more quickly and allows the complete GPU core to be turned off sooner than when using separate processing units.
This efficiency concept is illustrated below:
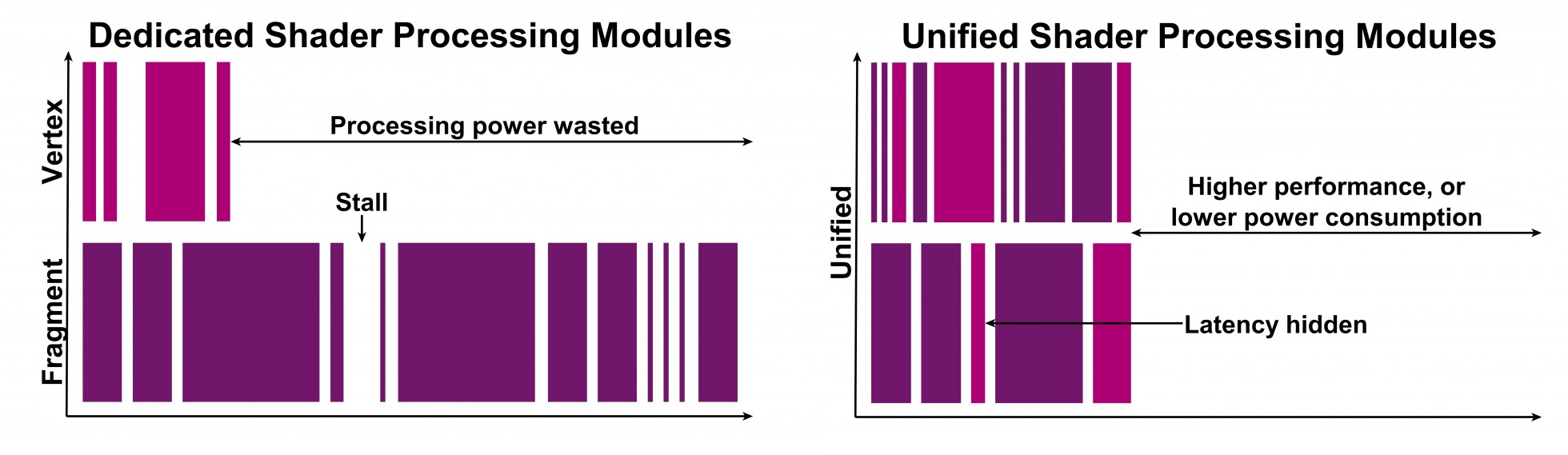 Dedicated shader processing modules (competing GPUs) vs. unified shader processing modules (PowerVR GPUs)
Dedicated shader processing modules (competing GPUs) vs. unified shader processing modules (PowerVR GPUs)
Multi-pipeline first, multi-core last
Scalability in GPU IP design is extremely important, as there is no one-size-fits-all scheme for the range of devices we need to support, from low-cost mobile phone requirements (with maybe a VGA screen) to the high-end set-top box market where gaming on a 4Kx2K screen is on the key feature requirements list.
Driven by efficiency, Imagination has focussed first on pipeline scalability in our PowerVR Series5/5XT cores. By scaling pipelines, the design scales up only the processing blocks which deliver extra ALU (GFLOPS) and texturing (Pixel Drawing) abilities, thus ensuring that support logic is not blindly increased.

The reasons behind this approach become clear when you consider multi-core scaling. With multi-core, a whole core design is copied across multiple instances. This scales absolutely everything, and is very inefficient since all support logic is copied. With multi-core scaling, silicon area investment basically doubles to achieve double the performance, whereas with pipeline scaling, it’s possible to double performance without having to double the silicon area invested.
This concept is illustrated below:

Imagination’s approach to scalability: multithreading to multi-pipeline to multi-core
It’s worth noting that this approach results in GPU cores with different levels of performance, as we scale the number of processing pipelines. Our Series5/5XT cores are ‘not equal’ amongst each other, as we have some cores with less performance and other cores with more performance, as they have more or less pipelines. This is important to understand when wading through the marketing hype you might see claiming that ‘higher numbers of GPU cores must be better’.
Keep in mind that the performance offered by a single PowerVR SGX544 core is universally far higher than the performance offered by any of our competitors ‘cores’ across GFLOPS and fillrate, as well as benchmark performance.
MicroKernel firmware flexibility
In an earlier article about Series5XT’s market leading feature set, I explained the importance of keeping cores in line with market requirements, but equally balancing this effort with other factors such as power consumption.
A key hardware feature which sits at the basis of our capabilities in this area is our PowerVR GPU’s MicroKernel based operation. The MicroKernel is software firmware which controls the GPU operation and data flow. This has two key benefits: first, the GPU becomes truly autonomous and events are handled locally rather than having to keep the main system CPU busy through costly interrupts. The second benefit is that this is a software-based approach and not a rigid hardware based state machine. This has given us the flexibility to adapt to new market requirements over time.
A nice example of the capability of the MicroKernel and how it has allowed us to deliver better user experiences over time is support for Priority Based Rendering. Today’s Android devices run every pixel on the device through the GPU, and this means that there are multiple concurrent applications rendering. It also means that all of these applications are also being composited by the Android Surface Flinger generating the actual Android user interface on a phone’s display.

All of this is done through the GPU using OpenGL ES API interfaces. Simplistic competitive implementations handle all of these concurrent renders through software scheduling, rendering each application, and compositing passes sequentially. This means that the GUI smoothness can easily degrade when badly-behaved or excessively complex applications run in the background. Through the Microkernel firmware, we can assign priorities to different render contexts, and this allows the firmware to influence the scheduling of tasks on our GPU to give higher priority to the compositor tasks. This leads to an always-smooth GUI experience even when expensive tasks run in the background. With a fixed state machine design, we would never have been able to adapt. Furthermore, offering a solid, smooth, fluid user experience would have been far more complex and taxing, possibly even forcing the GPU to become managed by the CPU to work around fixed state machine issues and limitations.
The usage of the Microkernel firmware not only provides ultimate flexibility, it also offers low power consumption. This is extremely important, since one of the biggest consumers of power in today’s SoCs is the CPU, and anything which can be moved away from the CPU is a good thing to help keep its power consumption in check.
In the next blog post, I will discuss how PowerVR SGX supports texture compression and why PVRTC and PVRTC2 are vital not just for reducing application size but for keeping power consumption and memory traffic at a minimum.
If you have any questions or feedback about Imagination’s graphics IP, please use the comments box below. To keep up to date with the latest developments on PowerVR, follow us on Twitter (@ImaginationTech) and subscribe to our blog feed.
‘Understanding PowerVR’ is an on-going, multi-part series of blog posts from Kristof Beets, Imagination’s Senior Business Development Manager for PowerVR. These articles not only focus on the features that make PowerVR GPUs great, but also provide a detailed look at graphics hardware architectures and software ecosystems in mobile markets.



